This project collection explores the algorithmic core of robot autonomy: model predictive control, reinforcement learning, state estimation, SLAM, and neural scene reconstruction. I implemented or extended MuJoCo control/RL experiments, PPO-style learning, particle-filter SLAM, quaternion UKF orientation tracking, HMM inference, policy iteration, and NeRF reconstruction.
- MuJoCo MPC (MJPC) sampling predictive control on cartpole, acrobot, humanoid stand
- PPO for the dm_control 2D bipedal walker (~888/1000 deterministic eval)
- Particle-filter SLAM on KITTI Velodyne LiDAR + GPS/IMU odometry
- Quaternion UKF for 3D orientation tracking from raw IMU (full marks)
- NeRF scene reconstruction from posed images (COLMAP + volume rendering)
- Policy iteration for stochastic grid navigation
- HMM inference and EKF parameter estimation
Course: ESE 6500 Learning in Robotics (Prof. Pratik Chaudhari, UPenn). Repo: https://github.com/cedrichld/learning_in_robotics
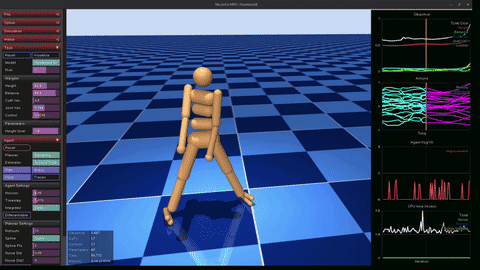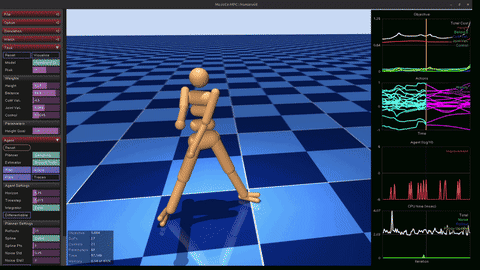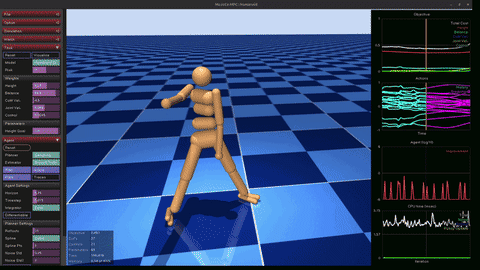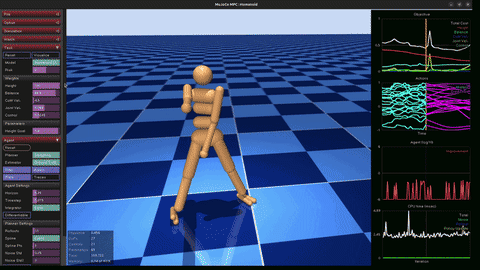
PPO Walker
Trained Proximal Policy Optimization from scratch on the dm_control 2D bipedal walker (24-dim observations, 6-dim continuous torques). 64-64 MLP actor + critic, clipped surrogate objective with GAE (gamma=0.99, lambda=0.95), KL early-stopping at 1.5 kappa. 8 parallel envs, 5M env steps. Final deterministic eval: ~888/1000.

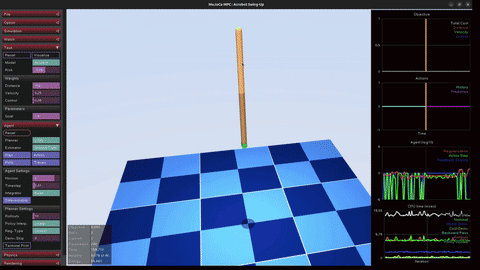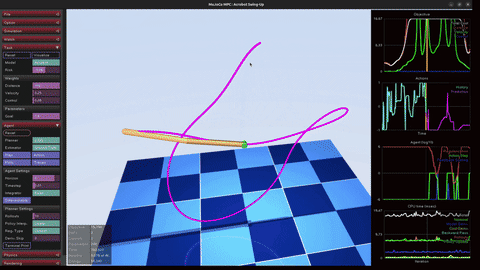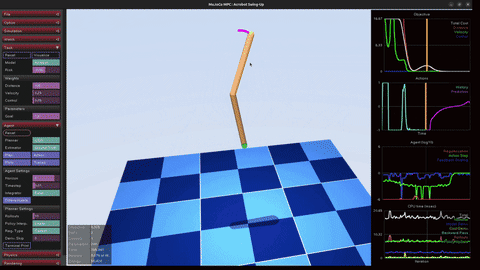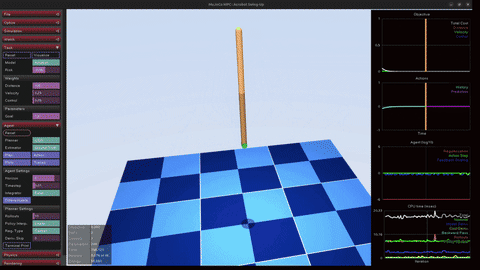
MuJoCo MPC
Real-time sampling predictive control in MuJoCo MPC (MJPC) across acrobot, cartpole, and humanoid-stand tasks. Each stabilizes a different non-trivial dynamics regime — useful scaffolding for translating sampling MPC ideas (close cousin of the F1TENTH MPPI work) into physical simulators.
Neural Radiance Field (NeRF)
Trained a NeRF from scratch to reconstruct a 3D LEGO bulldozer scene from 100 posed 2D images. The pipeline chains COLMAP structure-from-motion, ray casting with stratified depth sampling, positional encoding (10 frequency bands), a TinyNeRF MLP, and differentiable volume rendering with alpha compositing.

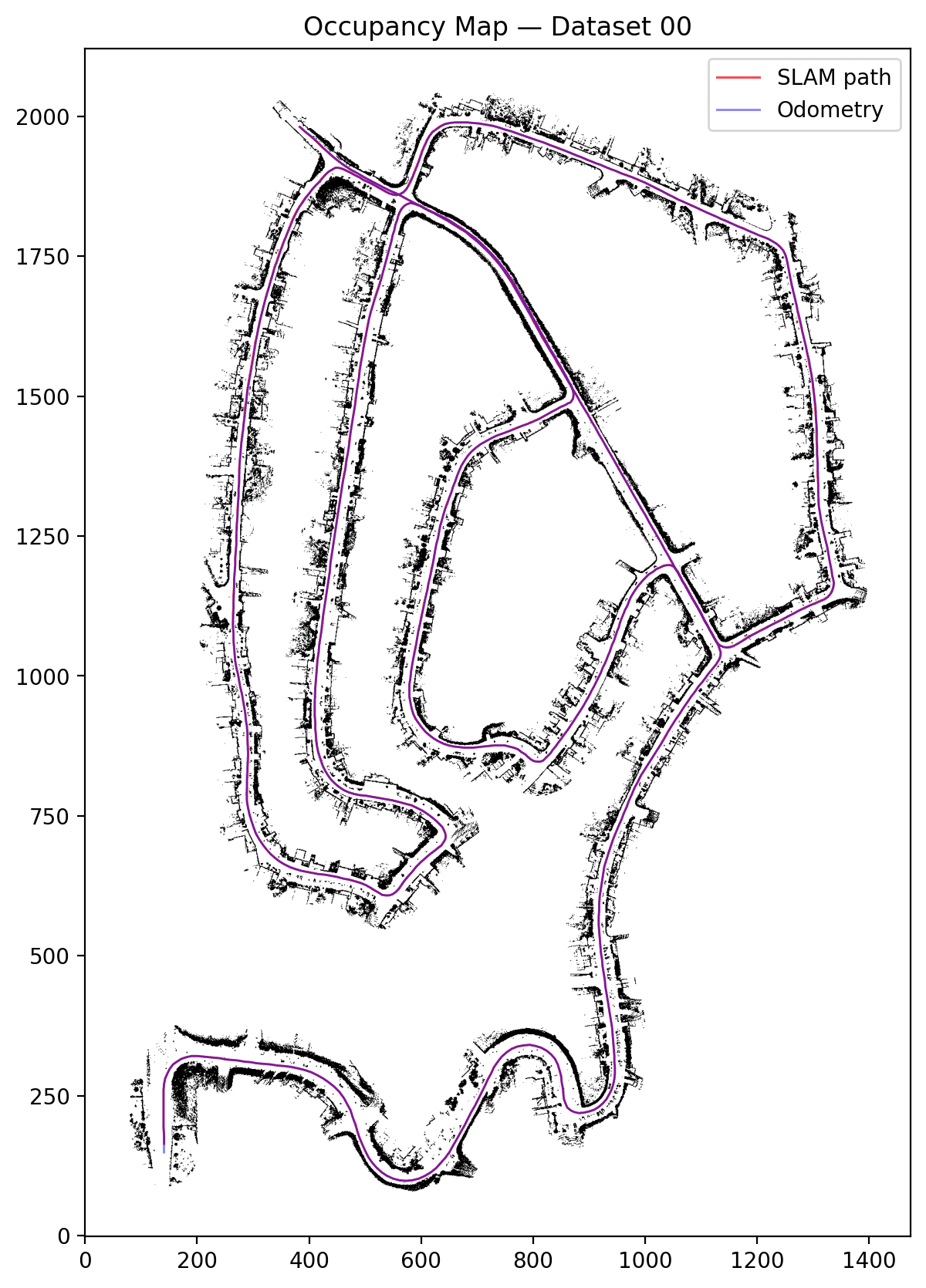
Particle Filter SLAM on KITTI
Implemented SLAM using a particle filter with Velodyne LiDAR and GPS/IMU odometry on the KITTI dataset. 50 particles, log-odds occupancy grid at 0.5 m/cell, stratified resampling. Road boundaries and buildings are clearly visible in the final maps across 4 urban driving sequences.
UKF for 3D Orientation
Quaternion-based Unscented Kalman Filter for 3D orientation estimation from raw IMU data. Sigma points on SO(3) via axis-angle error parameterization (Kraft 2003); anisotropic process noise decouples observable roll/pitch from less-observable yaw. Includes accel/gyro bias calibration tooling. Full marks (56/56) on the Gradescope autograder.
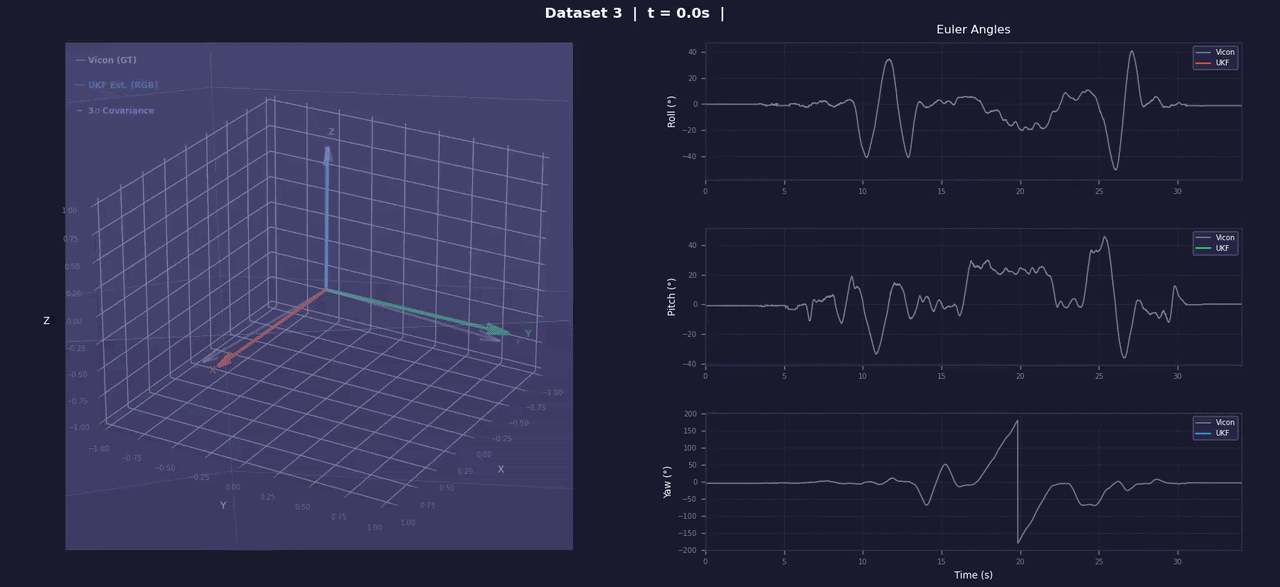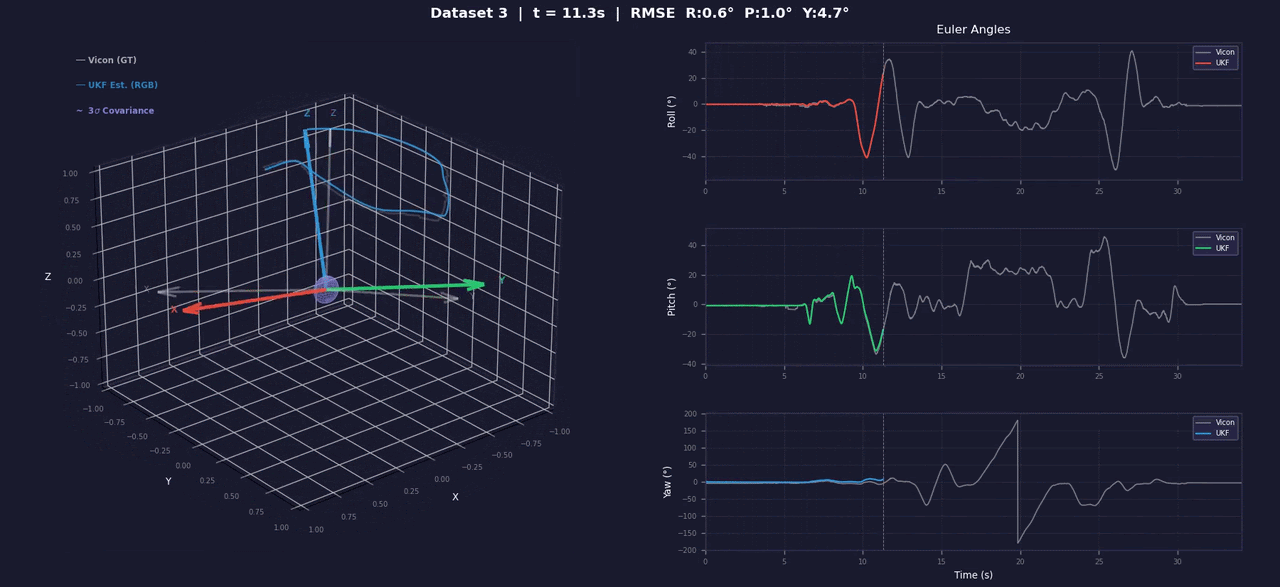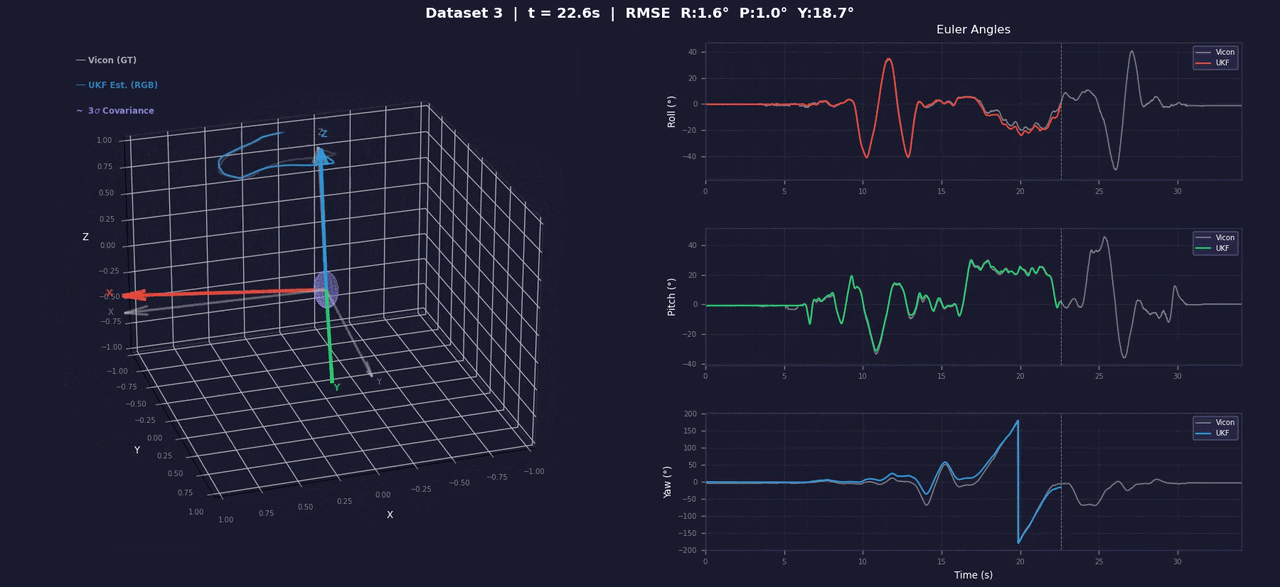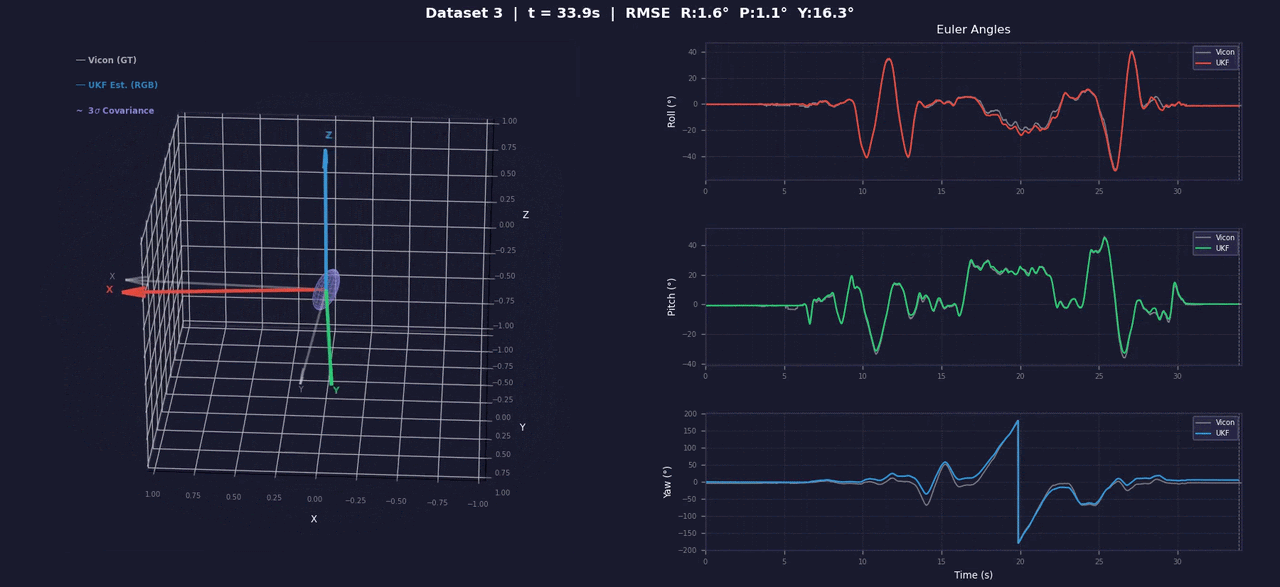
Integration validation on real IMU data:
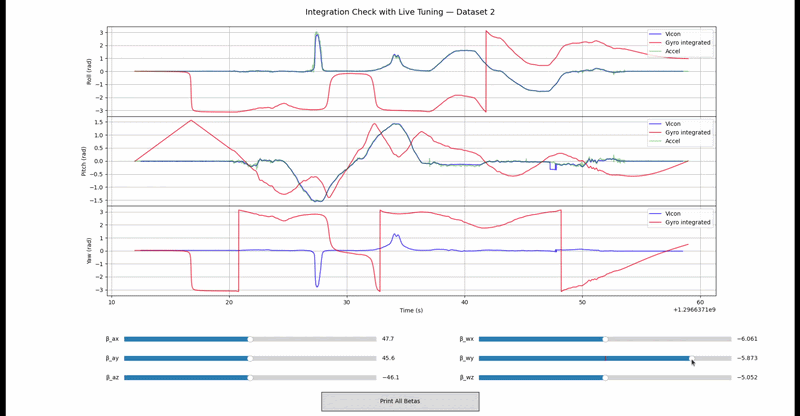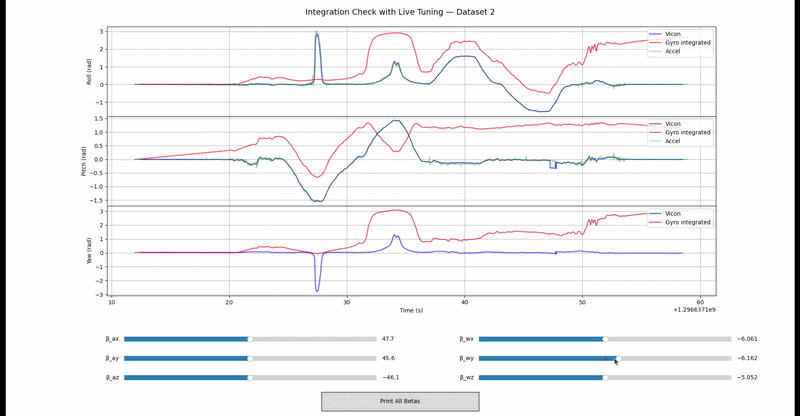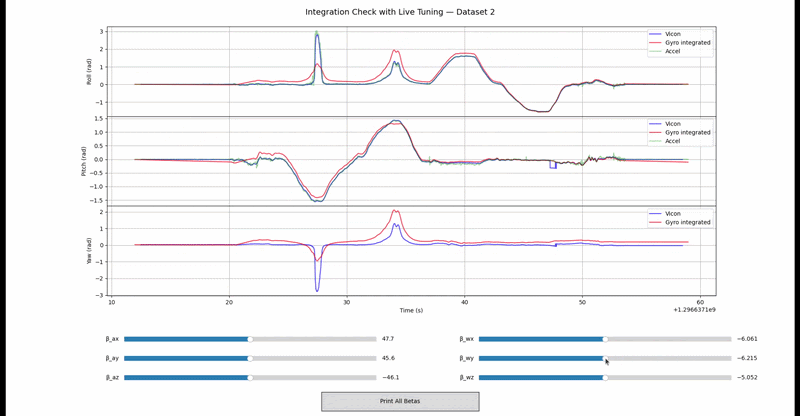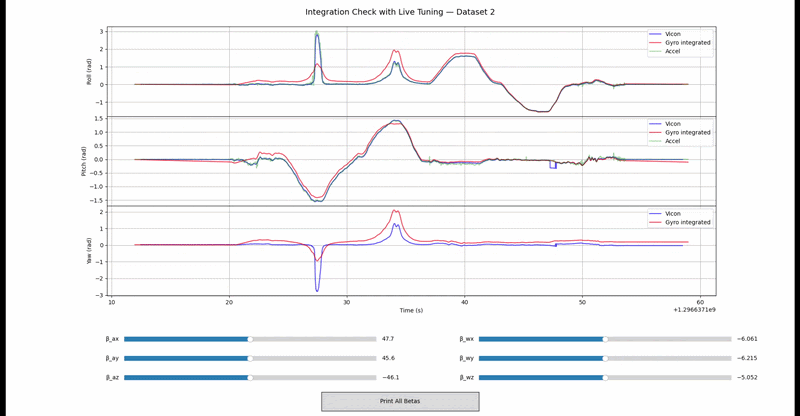
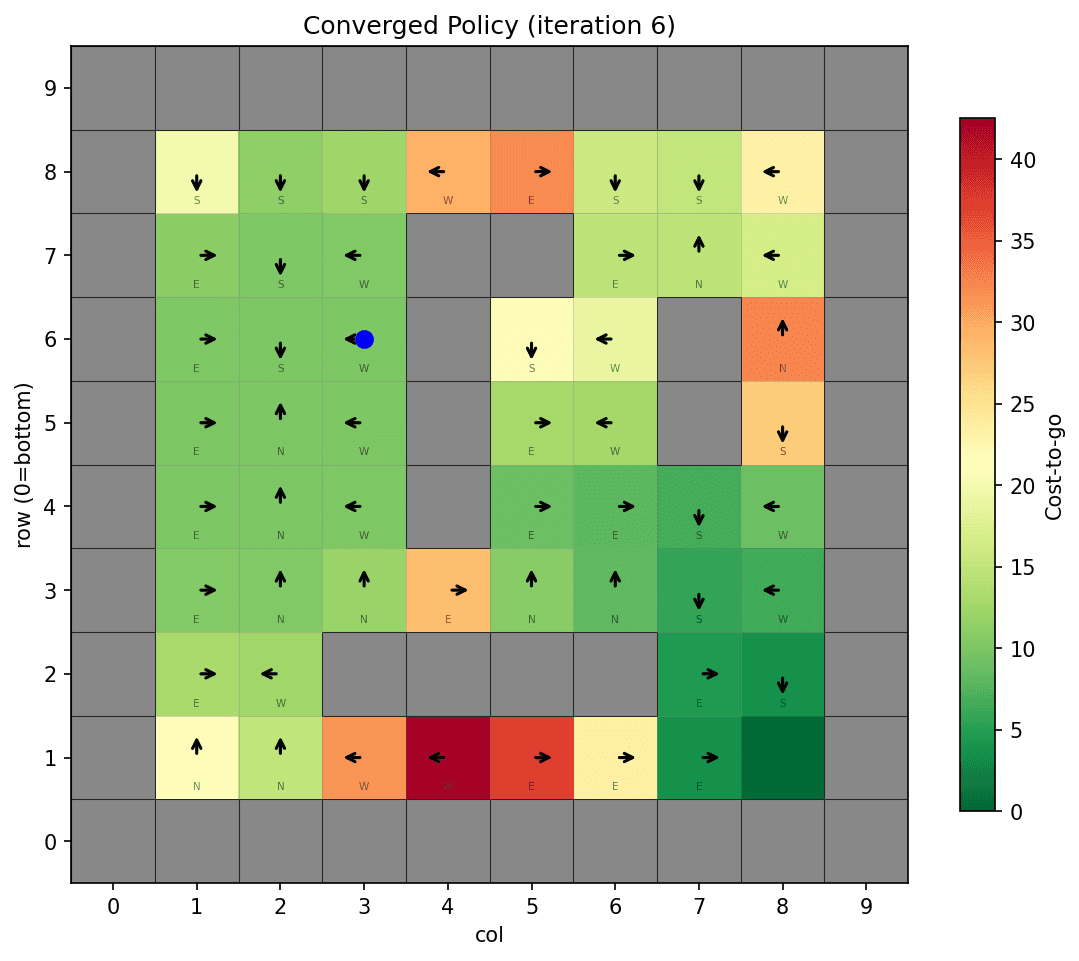
Policy Iteration
Optimal policy for a robot navigating a 10x10 stochastic grid (P(intended)=0.7, P(drift)=0.3) with sticky obstacles and discounted rewards. Converged in 6 iterations from a naive all-East policy to obstacle-aware routing via the policy-evaluation / policy-improvement loop.